Shrewd observers of GitClear’s trajectory could be forgiven for asking: “If this company 'started' in early 2016, why wasn’t it available to purchase until more than two years later?” Yes, well, about that.
This article will review what made it so insanely difficult to get our data processing reliable enough to be leveraged for all the features we launched in 2019. Of the many challenges we faced during these first few years of data processing, the most time-consuming was the challenge of de-duplication.
If “removing duplicates” sounds boring to you, then you’ve just discovered the first reason that so few of our competitors dedicate sufficient resources to this problem. It’s boring as hell to work on, and a "success result" amounts to an unsatisfying “things are less bad.” Adding a flashy feature like Open Repos is what gets developers excited to engage. Removing duplicate committers... not so much.
linkA Very Brief Primer on Git Commit Data
The second reason that this is a seldom-solved problem lies in the design of git. Technically, to make a commit, one needs provide only:
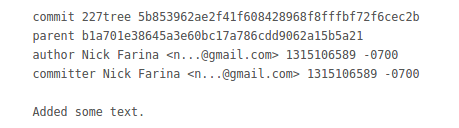
In order of their appearance in the git commit screenshot above:
0) A pointer to the repo's current content (227tree 5b85...)
1) Shas of parents (parent b1a70...)
2) The commit's author (name, email, time of authorship)
3) The commit's committer (name, email, time of commit)
4) Checkin note (Added some text)
No branch data. No diff information. No enduring sense of committer identity. No pointers to other commits with known matching content. Anyone who has had the misfortune of dealing with a large data set of semi-duplicated data should already see where this is going. A git commit holds precious little structure to which a de-duplication effort can attach.
linkDe-duplicating Committers
There may be fewer distinct individuals than it appears

Getting a consistent interpretation of the committers in a repo is the first battlefront in the war to turn messy git data into reliable git data.
There are probably some who wonder why this is so hard. It's not like people change their name or email address that often, right? Assuming that a developer keeps the same name and email address, there is no ambiguity about the identity of a committer. So far so good.
Where the situation starts to get sticky is when the developer sets up a new workstation. How often does this happen? Well, most developers work from at least two computers: a desktop and a laptop. Each of those workstations probably gets upgraded every 2-4 years. Add in some occasional OS reinstalls, and ballpark math says that the average developer works on about 13 workstations every 10 years. That's 13 separate opportunities for them to create their .gitconfig file with a slightly (or totally) different name, or with an updated email address (how many email addresses have you used in the last 10 years?).
If committers sharing a name make commits from different email addresses, that's technically a different committer. If they use the same email address but one workstation knows them as "Bill Harding," another knows them as "William Harding," and a third knows "wbh," that's three different committers. Even if the casing of the name changes, that may or may not be a different committer, depending on what database is interpreting it.
The only failsafe way to eliminate duplicate committers would be letting a manager dictate which committers get merged. This functionality is offered by all the major git data processors, and it seems fine, until you start running the numbers. If you administrate a team of 50 developers, the math above says you're probably implies you'll be looking at about 50 * 1.3 = 65 new workstations per year on your team. That’s 65 situations every year where developers are going to be asked to enter their name and email anew, and there’s a good chance that half of those will be at least slightly different than the last time they were asked.
linkDe-duplicating Commits
Valid and meaningful commits do narrowly edge out the alternative in aggregate, but that still leaves almost 45% of all commit shas containing no unique work. Here is a non-exhaustive list of different paths by which the same content is committed repeatedly, or ignore-worthy work is committed:
Rebasing. If the developer rebases, every rebased commit is technically a new commit, with a new committed_at timestamp. Unless the data model can recognize commit pushed repeatedly with new commit times, then teams that rebase will appear to have twice as much commit activity.
Squash strategy. If the team adopts best practices as espoused by esteemed developers like Andrew Clark, they might choose to make a series of N commits (which are just save points, after all), and when the commit is ready to move to master, it becomes one commit. From the standpoint of repo history, this makes a lot of sense. But if a data processor hopes to show day-to-day work before it reaches master, something’s gotta give. Either you choose to ignore the in-progress commits, or you ignore the squash commit, or you double count work that was done.
Merge commits. There is no inherent notion of a “diff” or “what changed in this commit” to git. The diff you see presented by GitClear et. al is simply the data processor interpreting what changed between content that was pushed in commit A and commit A'. Thus, while a merge commit will often contain no difference between the lead commit and its parent on the feature branch, it will contain an entire PR’s worth of difference between itself and its parent on the default/master branch. Complicating matters further, a merge commit might itself contain novel changes — though it ought not — but it might. Should merge commits count toward the commit count when they include no novel content?
Force pushes. The most common way of developing a feature in git is to work on a separate branch that can be re-written in whole at any time. "Re-writing the branch" (aka "force pushing commits") is necessary if the developer has rebased the branch's commits onto master since they were last pushed (very common). Every time the branch is force pushed, a new set of commit shas, with new commit times, will enter into the repo. Every force push is an opportunity for a naive commit counting algorithm to drive up its interpretation of how many distinct commits have been made.
The list could go on, but the point feels adequately made that git never truly commits to that which bears the name “commit.” Commits are a fluid concept that constantly mutate and frequently re-appear in slightly different circumstances.
linkDe-duplication: Not fun. Not sexy. Just essential for reliable insight
The work required to ensure reliable, consistent, and distinct committers/commits is very boring. The fact that you’ve read this far into our article can only be a testament to the fact that you’ve personally dealt with the consequences of this very boring problem hindering your ability to rely upon your data.
Git was not built with data visualization in mind. The limited signal git provides is a significant hindrance when extracting the truth about what work was distinct and meaningful.