For the past year, we've been piecing together a new product that uses our company's flagship metric, Line Impact, to lower the barrier to entry for contributing to open source projects. After a feverish race to finish line, we're excited to announce that Open Repos is now available to the public -- try it out here .
Open Repos (alternatively, "Oreps") is built to make it easier to read and contribute to open source repos. It does this by providing a commit browser (e.g., in Tensorflow or React or Rails), a directory browser (e.g., in Vscode or Angular or Postgres) and the ability to quickly see what's changing between releases (e.g., Tensorflow or Ansible or Babel).
The rest of this post uses an FAQ-style layout to explain what Oreps is and how it can benefit developers. Feel free to skip to any section:
linkWhat can you do with Open Repos?
Here are some things you can do with Open Repos:
Repo Maintainers
Send repo followers a URL that automatically summarizes the issues resolved and code changed by release
Send new contributors a repo browsing experience that shows code ownership by directory
Vet new contributions more rapidly
Open Source Contributors, Prospective Contributors
Decide which open source project writes code you can understand well enough to contribute
Get updated when an especially large change is made to a repo you care about
Locate which directories are the most active during initial orientation
Create a “living resume” for prospective employers/clients
Open Source End Users
Avoid adopting open source repos with negligible velocity, when relevant
Find most active open source product in a particular space (e.g., WSYWIG editor)
Donate to developers and
Track the follow-up results after making a donation
linkWhy did we build Open Repos?
Over the past 10 years, institutions like code.org, Y Combinator, and others have helped advance the idea that everyone ought to try their hand at software development. At this point, it's practically common knowledge that if you have interest and aptitude for building software, that's probably what you ought to be doing.
By many measures, the software industry looks to be growing at a pace of about 20% annually. When a full stack developer with 8 weeks of training can command a salary comparable to a general practice doctor with 8 years of training, you know that this is a wild time to be alive.
But with this influx of opportunity comes a new set of challenges for the eager newcomers seeking their first software job. How can they prove their mettle with only a year or two of experience? How can they differentiate when they're swimming in a sea of similar-on-paper applicants? With every company bringing its own different -- seemingly arbitrary -- interview process, it's a daunting prospect to stand out from the field. Suddenly, that 20% annual growth of software developers begins to feel more like an impossible competition than an unprecedented opportunity. Especially if one hopes to get a job at a resume-boosting company like Google, Airbnb, or Stripe.
Even after a new coding graduate secures that coveted first job, the challenges continue. Experienced developers forget how many hurdles stand in the way of progress for a new developer. For starters, they need to understand git. How do they commit to a branch, merge it to master, manage conflicts, etc? How do they compile the complex dependencies often required by a professional development environment? Where do they look for code that can be used to learn the conventions that are currently used by their team (often distinct from the conventions prescribed by the team's inevitably outdated documentation)?
For new developers, one of the hardest problems is just figuring out what questions to ask. It's like flying to China and trying to figure out how to rent a flat. Where would you even begin?
Of course, experienced developers aren't immune to these pains. They need travel no further than GitHub to encounter scores of technologies and conventions that can be just as foreign to them as their own tech stack is to a new hire. While the experienced developer can rely on some types of knowledge being transferable (e.g., git, command line, Jira), it's still often a tedious process to re-learn the vocabulary of a new technology well enough to formulate what questions to ask when they get stuck.
If any of this sounds familiar to you, then, on an intuitive level, you already understand why we built Open Repos. We think it's possible to lower the barrier to entry to become fluent (and eventually proficient) in unfamiliar code. If we're right, then it would follow that Open Repos should drive up the level of participation across open source repos. In particular, Open Repos could help accelerate the career of new developers by giving them a perfect jumping off point to show potential employers that they're capable of comprehending a large-scale project, and contributing code that ships. With any luck, they might find that they enjoy open source development enough that it becomes a long-term hobby?
linkWhat are some tangible examples of how Open Repos can benefit me?
Open Repos benefits developers by providing a rich visual window into what's happening in git.
Commit Activity Browser
Because GitHub, GitLab, and Bitbucket all use essentially the same set of visualizations to represent commit activity, it's easy to forget how far divorced these representations are from the practical questions that developers often want answered. Questions like:
Which Github/Jira issues are resolved by recent work? Can I follow the code that implements those issues well enough to potentially update it later?
What's the style/velocity of code written in this repo? How can we reward those improving the code base for the rest of the team?
What exactly changed between the version of an Open Source library used by my project vs later versions? Is the project still evolving, and how much?
For these questions, we provide the Commit Activity Browser (aka "CAB"). It's described in depth in the following section. The purpose of CAB is to make it fast to browse temporally-related code -- typically code that is soon to become a PR. It does this by organizing commits per-committer, and sizing the commits based on their Line Impact.
Directory Browser
This feature gives developers a sense for where in a project work is happening. The three providers currently represent where work is happening in nearly identical fashion. Whether you use GitHub, GitLab, or Bitbucket, the directory browsing experience is lacking answers to common questions like:
Where has the majority of the code been written during the past n weeks/months/years?
Which developers have been principally responsible for authoring work in X directory (i.e., who might I direct my questions about X toward)?
Which directories evolve at a high velocity, and which are more like tar paper for those who have the misfortune of inheriting them? The former is often well-factored code, whereas the latter tends to be tech debt.
Releases List
This section is already getting long, so we won't delve into how Open Repos helps visualize what work took place on a per-release basis. Here's a glimpse at how that currently looks for Facebook's React repo:
Each Open Repo provides a list of recent versions released. Within each version, one can dig deeper to learn which issues were resolved in the release, which directories and files changed, and how much that version evolved the repo's code base
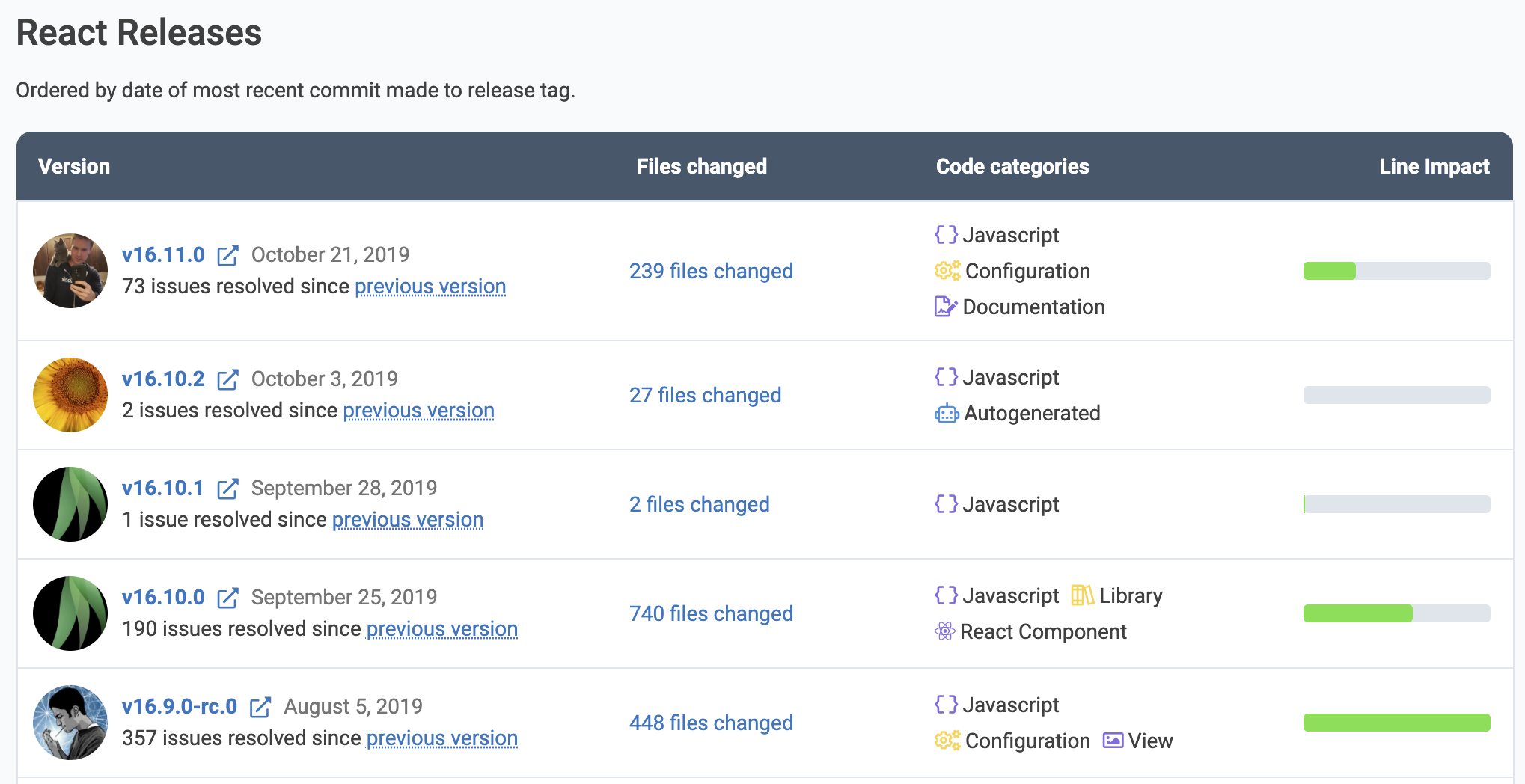
If you happen to work at a company that uses React, Angular, Bootstrap, Tensorflow, Vscode, Postgres, or any of the other Open Repos we currently process, you can probably extrapolate how this information might help when you're mulling an upgrade.
linkWhat is the Commit Activity Browser?
The left bar shows which committers are active in the repo -- this screen grab is the Facebook React repo. To the right of a committer are their commits, sized by their Line Impact, and sharing the same color.

The Commit Activity Browser was originally built to save time keeping up-to-date with the code contributed across our company's ~15 repos (scattered across three GitHub organizations). The more repos we accumulated, the less practical it became to use GitHub to try to digest their activity. This 2 min video captures the spirit of the directory browsing experience on GitHub vs. GitClear.
A top-line goal we wanted to achieve with Commit Activity Browser (henceforth, "CAB") was to give code reviewers a stable sense of how a commit fits into the bigger picture of what's happening in a repo. Code takes its most potent form in context. When you use CAB to view commit activity, we keep all related commits stuck to the top of the page. It's meant to be like a map of the team's recently authored code. This helps you establish a sense for how a particular commit or Jira fits into all recent activity, which in turn can accelerate code review.
Building CAB, we've tried to use transitional effects to reaffirm how the user is moving through the commit map. Best case, the transitions also make the experience more satisfying. Inasmuch as GitClear has a developer mission, it would be "make code satisfying to read." In literature, great readers seem to have the most potential to become great writers. Code is similar enough to writing that the same might apply here.
linkWhat is the Directory Browser?
Directory Browser illustrates which directories have had the most activity over a selectable time interval.

Directory Browser (née File Browser) was initially built to help Bill understand libinput, an open source project that he's been striving to push forward over the past year. If you're a developer, the scenario might sound familiar. You're trying to grok a new repo. You can see a list of commits were made over the last few days, but that doesn't do anything to help answer the practical question of "what file(s) do I open to see recent, relevant code related to issue X?" You need a broader sense for where development is happening in order to know which files to open in your IDE.
Trying to answer that question, I've often resorted to the only option that was available pre-GitClear: reading the update timestamps on directories to surmise where the interesting code might be lurking. It's hard to overstate how gross it feels to rely on directory timestamps to guide browsing. 🤢 The efficiency of that method approaches zero.
If you'd like to visualize how all this works in practice, this two minute video summarizes the differences between browsing directories on GitHub and GitClear.
linkIs this free? How will it be supported?
Open Repos is free for users, and shall remain so forevermore. 🎁🎄
Of course, it isn't free for us to build or host. Like Notion.so (or Amplenote), GitClear is built to support itself chiefly through old-fashioned profitability (abetted by low costs). Our "investment thesis" is that less investment corresponds to better long-term focus. As long as Oreps create enough value that some of the free users become paying commercial customers, we'll be in good shape to continue fleshing out what we can offer, using those customers as guidance.
Fair warning: in the earlygoing, our ability to answer emails/comments/bug reports about the free service will be limited. But we have been and will continue to be relentless in improving data quality before adding features.
If GitClear provides value to you as a developer, please consider signing up for our paid product. The commercial product takes the ideas in Open Repos and adds several more layers of insight, such as PR contributor analysis and a graph to identify the full cost to developer throughput caused by meeting-heavy cultures. Price calculator available here. Per this analysis of code measurement in 2019, our pricing is competitive for the space.
linkI’m a repo maintainer that would like to use this to automate generating my version release summary
Cool!! We have been hoping you would find your way here! In the longer term, we intend to allow GitClear Orep releases to be embedded in other pages, so you can share a synopsis of a new release from within your website / blog /etc. In the meantime, you are welcome to create an Open Repo account and request an import of your repo. Once we process it, you'll be able to link to all the releases for your project through a consistent url format we provide.
If you're a project maintainer that would like to use GitClear, please email us at hello@gitclear.com and let us know what project you maintain and what your current solution to announcing new versions is. We'll use your email to help us prioritize the features we'll soon add on behalf of open source owners.
linkHow reliable is this data?
Ensuring data reliability is the most important job we do every day. It is a challenge that obsesses us. But there is good reason that billion dollar companies like GitHub, GitLab, and Bitbucket haven't already implemented what GitClear is attempting: it's "rocket science"-hard to interpret the vagaries of a git repo in consistent fashion. Everything from "what is a committer?" to "what is a branch?" and even "what is a commit?" are all far more complex than they appear at first blush. Git is the quintessential example of a domain where, the more you learn about it, the less you realize you know.
The good news is that this is a solvable problem. We've made huge strides over the past four years in iterating our way toward a metric that consistently and reliably measures the degree to which code evolved. If you go looking for rough edges, you can probably find them. But data consistency is a core value of our company. We are committed to launching less features and creating less new content so long as our customers can identify data anomalies. We're comfortable putting in the hard work required on behalf of generating trustworthy data in the long-term.
Update: we've added a "Data Confidence" label to each version release page:

Hover on the rating when you see it, and we'll pop a tooltip to explain how reliable the data is for that specific repo+version.
linkWhat’s next on the roadmap?
We have made a lot of progress quickly as we've used GitClear's insights to improve our own throughput. A year ago, none of Commit Activity Browser, Directory Browser, or Open Repos existed. We plan to continue to improve the quality of our product at an accelerating pace. More money wouldn't hurt.
Here are five incremental improvements we expect to pursue over the coming year:
Equip GitClear to deal with Orep load while keeping response times snappy
Continue polishing our On Premises offering (publicly available as of October 2019)
Add and improve documentation
Integration with Github Sponsors, GitLab
Add a data API so users can get access to our interpretation of the commit graph and Line Impact
Over the longer-term, we’re extremely interested in building a complement to Line Impact that measures the aftereffects of implementation. It might be dubbed something like "Clear Impact." The metric will estimate how much each commit contributes to the long-term maintainability of the repo. Our thesis is that commits that add code tend to reduce maintainability, and vice versa. This corresponds to the common knowledge that many Senior Developers impart their greatest value via code removal. Being able to simplify code without breaking it requires experience, talent, and the wherewithal to remain focused while iterating. Those who can make an existing machine simpler and no more broken than it started are not yet well identified by Line Impact, for incidental reasons. Clear Impact (or whatever we call it) will aim to isolate the commits in which tech debt is reduced, so we can identify/reward the tech debt reducing heroes within a repo.
linkHow to describe GitClear the company? Who is to blame for this?
If we may borrow a summary of GitClear from a recent chat with a professional investor: GitClear is the company that got left in the dust while GitPrime soared to a $170m exit. 🦄 Both companies began their journey circa 2016. While GitPrime dreamed of, then realized, capturing big fish like Adobe as customers, GitClear dreamed of iterating on a metric that could reliably measure the degree to which code evolved. The GitPrime plan sounds a lot cooler. And, to this point, it has yielded substantively greater returns than our plan to methodically iterate.
The CEO and CTO of GitClear is Bill Harding. Bill started programming with Qbasic in 1992 because there was nothing else to do in his hometown of Poulsbo, WA (at the time, a farming community of 4,000). After folding his BBS (look it up, kids) following a hard drive crash in 1995, Bill has continued pursuing his lifelong passion for programming and entrepreneurship. In addition to GitClear, Bill has founded and currently operates Bonanza.com, Background Burner, and Amplenote. The three products are currently bundled as one company under the ad hoc moniker "Alloy." The common denominator behind Alloy products is a commitment to everyday dogfooding.
To date, Alloy has funded GitClear development through the proceeds from its more profitable products. This helps explain some of the more curious aspects of our journey -- in particular, that we've spent nearly five years methodically iterating the "single, reliablic metric" idea, even though we didn't start processing data for external customers until 2018.
In terms of our needs, if you happen to be in possession of 1) $3-5m without requiring a board seat, or 2) programming talent and passion, we would love to hear from you at hello@gitclear.com! 🙏 Our pitch is that we're demonstrably driven by the long-term wellbeing of our employees and our product. Every time our competitors pursue near-term financial victories at the expense of product quality, GitClear can get a tiny bit more differentiated.
linkOpen Repos is useful to me, can I help make it better?
Firstly, thank you for being open to embracing a new idea! We appreciate that developers tend to be highly rational thinkers that start skeptical when a new idea comes along. Respect must be earned and maintained. If you enjoy Oreps enough to want to make them better, we would love to utilize your enthusiasm.
The best ways to help us improve code visualization as of 2019 would be:
Sign up. The more users log in to GitClear, the more potential quota we have available to keep our data updated. You'll find a link to sign up from any page within the Oreps experience.
Work for us. Especially if you are handy with devops, we could seriously use your help. If you're a Lead Developer with an eye for detail, we would love to hear from you. The CEO will read all emails sent to hello@gitclear.com.
Tell your friends. We need all the goodwill, positive reviews, and customer we can get during this formative stage.
Also, got integration suggestions for other providers? Most, but not all, of the best open source projects currently reside on GitHub. GitLab didn't seem particularly interested in facilitating our integration when we last mentioned the opportunity. If you were us, which provider would you integrate next?