If Amplenote and GitClear go on to get full product/market-fit, no small part of that will be attributable to how well GitClear incentivized its developers to defy the odds on “how much a small team can get done?” As of the publishing of this post, we’ve been working on about four products with a team of three devs, and our two star products are mingling with profitability after raising $0 in ~2 years since being launched. There is little reason to think that our weird approach to development could triumph in a competition against competitors with 100x resources (ClickUp, Pluralsight, et al), unless we beat the odds on “progress per dev per day.”
How to do it? Hopefully, by high-level calibrating toward a long-term goal of “getting more done.” For example, I’m currently writing this from what GitClear calls my most productive week of the past year. Here are the past six months:
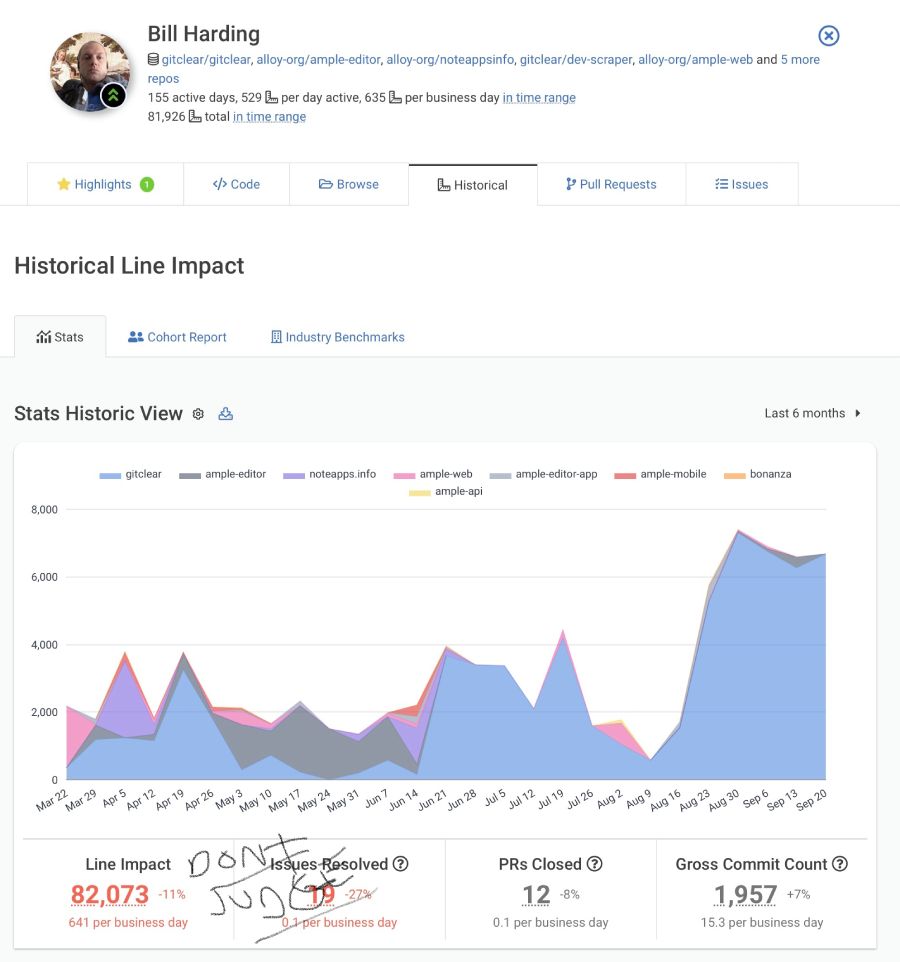
I’m not sure how many people naturally think & remember in numbers, but I’ve always found it easiest to conceptualize relationships by the numbers associated with them. For example, when I start listening to a new band on Spotify, one of the easiest ways for me to catalog them in memory is by their monthly active listener count. This gives my memory purchase to associate my favorite bands together in groups, based on their popularity.
When it comes to looking at a graph like above, which approximates my dev productivity, seeing these high numbers helps me collect together the weeks that were abnormal, so I can think about them as a group:
How was mental wellbeing during those weeks? Are they the kind of weeks I’d be happy to keep repeating?
How did the product look before and after?
What systems was I working on? What was I doing to those systems?
To start with the first, emotional question: these surge weeks feel pretty damn invigorating tbh. One part of that is the feedback loop of seeing high numbers and intuiting that means “good.” But more of it is that a high Line Impact week only seems to happen when I’m working on systems that I understand very well.
And that gets to the third question. These weeks where I’m averaging ~1,000 Line Impact per day are weeks where I’m doing large-scale updates of legacy systems. During the past three weeks, I’ve probably averaged 15-25 commits per day, working 10-12 hours per biz day. So there’s definitely a lot of LoC changing. But in particular, it’s a lot of old model files that haven't changed for a long time, save for occasional cruft accumulation in response to bugs, so Line Impact potential is ripe. When updating legacy code, deletion opportunities abound, and Line Impact pretty clearly loves deleting old code:

To get a bit more specific, the past week I’ve been migrating our data model for handling Jira/Github issues. Previously, we were storing all Jira data (title, description, etc) in a per-repo model, based on the now-false assumption that work on a ticket would always happen in one repo. In a world where GitClear is aiming to offer better DORA support than any other Dev Analytics service, we need to have our Jira processing down cold, in DRY models where the single source of truth is clear. To get there required about 10 database migrations over the past week (the “db” directory, below):

Along with the database migrations were So. Many. Tests. That needed to be deleted/updated/added to accommodate so many changed assumptions. Jordan, Matthew, and I have swung pretty emphatically from the “tests meh” to the “tests plz” bandwagon since the halcyon days of 2015. Odd it took so long, since I have been aware of those who evangelize tests since at least 2005, but, when Bonanza was small, it was hard to appreciate the incremental benefit of tests vs. just testing the feature in a browser as it’s being developed. Also, the ways that we wrote tests sucked. For me, the intuitive benefit of leading with tests really started to set in after maintaining a project for 3-5+ years. Both GitClear and Amplenote now fall in that zone, so it has become an important high-level goal of ours to incentivize thorough test coverage (and docs).
In the future, I have to imagine it will become more commonplace, at least among executive devs, to aggregate data on one’s own output and the circumstances surrounding the higher weeks. It’s a very gradual process to appreciate the benefits of knowing when one is getting more done. Executive devs will be drawn toward it once they know it exists, and no one else cares enough to read what could be written about it.
Not so unlike Rich Footnotes in that regard.