GitClear's "LLM-Attributed Work" visualization shows what percentage of committed code in your repositories was written with the assistance of AI coding tools such as GitHub Copilot, Cursor, Anthropic Claude Code, and Google Gemini. This page appears in the "Browse" tab to give engineering managers and team leads a data-driven view into the degree to which AI assistants are contributing to the codebase — not as a judgment, but as a starting point for understanding how AI adoption is influencing code composition, quality, and maintainability over time.
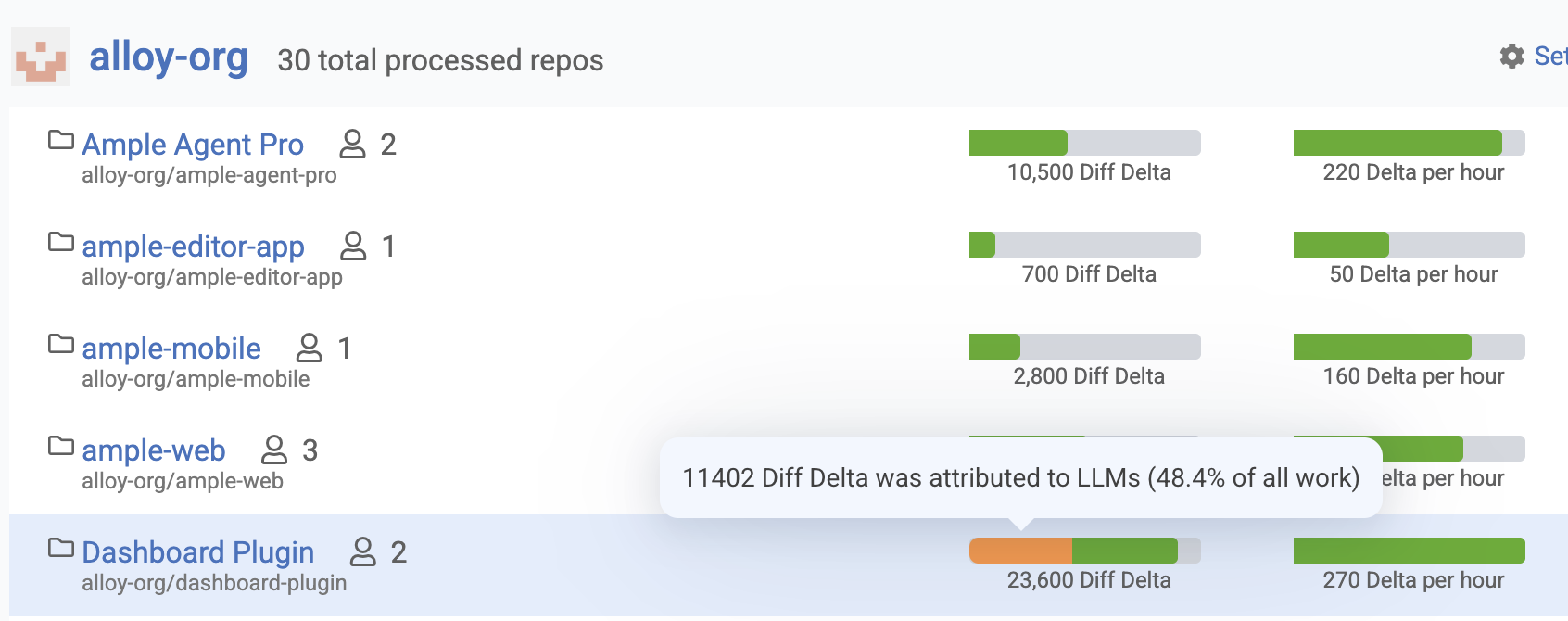
How much work in each repo was authored by LLMs?
linkHow GitClear determines per-repo, per-file AI authorship
Ascertaining how much code was authored by an LLM is a multi-layered problem, and GitClear uses several complementary signals to arrive at an estimate. The most direct source of attribution data comes from API-level telemetry provided by AI coding tools themselves. GitHub's Copilot Usage Metrics API, for example, exposes data about code completions and chat interactions at the organization level, including how many suggestions were accepted and by which developers. When your organization connects a Copilot API token to GitClear, we can cross-reference Copilot's acceptance telemetry with the commits that land in your repositories, giving us a reliable signal for which lines were generated via tab-completions or Copilot Chat suggestions. Similarly, tools like Claude Code leave explicit markers in commit messages, the Co-Authored-By: Claude <noreply@anthropic.com> trailer that GitClear can parse directly from your git history to attribute specific commits as AI-assisted. Cursor and other tools that operate through IDE-level integration are detected through analogous signals where available, such as commit message conventions or API data shared by the tool provider.
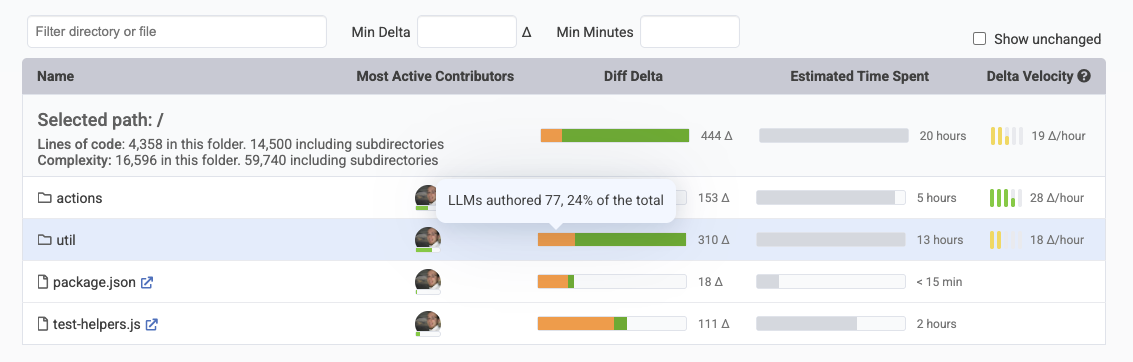
Navigate into a repo to understand how much work in each file and directory were AI-authored
Beyond these direct signals, GitClear also applies its own analytical heuristics to estimate the likelihood that a given code change was AI-influenced. GitClear's proprietary classification engine already categorizes every changed line into one of seven code operations: Added, Deleted, Moved, Updated, Copy/Pasted, String Substitution, and No-op; these classifications can reveal telltale patterns associated with LLM-generated code.
For instance, GitClear's published research on over 211 million changed lines of code has consistently found that AI-assisted development correlates with elevated rates of "Copy/Pasted" (cloned) code and reduced rates of "Moved" code (which typically indicates refactoring). When a commit exhibits a high proportion of newly added code that duplicates existing blocks elsewhere in the repository, or when the code is subsequently churned (reverted or substantially revised within two weeks of being committed), these patterns serve as secondary indicators that supplement the direct API and commit-message signals. The combination of direct telemetry, commit attribution markers, and behavioral heuristics gives GitClear a more complete picture than any single detection method could provide alone.
linkLLM Attribution by AI Provider
Visualizations within the AI Usage Stats can show an aggregate percentage of "LLM-Attributed Work" for the selected time period, broken down by the AI tool responsible.
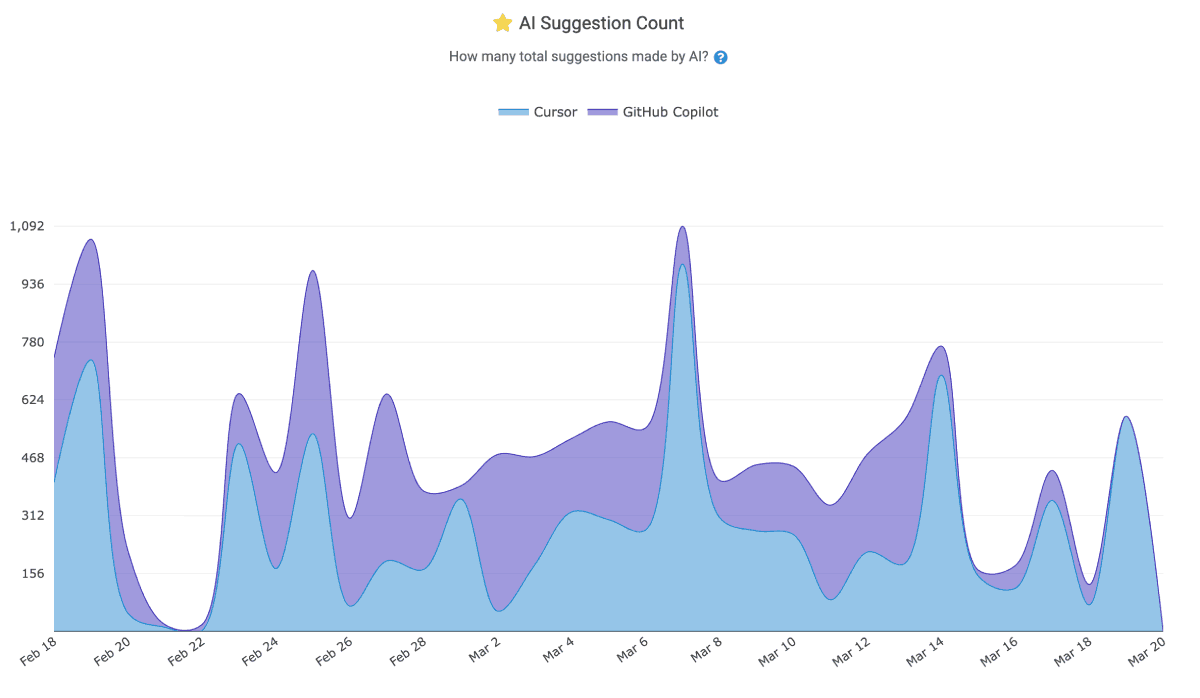
AI Suggestions made by various AI providers for the team & duration chosen
You may see separate segments for Copilot, Cursor, Claude Code, or other recognized assistants (e.g., Gemini, Augment), depending on which tools your team uses. The chart allows you to track trends over time -- for example, observing whether AI-assisted code is increasing quarter over quarter, or whether certain teams or repositories rely more heavily on AI than others. This data can be filtered by the same dimensions available elsewhere in GitClear: by repository, team, individual developer, or date range, making it straightforward to correlate AI usage with other metrics like Diff Delta, churn rate, or code quality goals.
linkWhy this matters?
The purpose of tracking LLM-attributed work is not to discourage AI tool adoption — these tools can meaningfully accelerate development when used thoughtfully. Rather, the goal is to provide the visibility that engineering leaders need to make informed decisions about where human effort has been concentrated, and where AI-generated code might deserve closer attention.
One of the most practical benefits of LLM attribution is understanding the distribution of human effort across your codebase at the directory level. Directories where the vast majority of code was written by humans represent areas where your team has invested significant cognitive effort — understanding business logic, making architectural decisions, and iterating on edge cases. These are the parts of your codebase that embody the most institutional knowledge, and they deserve to be treated accordingly when it comes to review priority and refactoring care. Conversely, directories where a high percentage of code was AI-authored are likely to be more straightforward candidates for future AI-assisted refactoring. If an LLM wrote the code in the first place, there's a reasonable expectation that an LLM can also understand and restructure it effectively — making these areas natural targets for automated cleanup, de-duplication, or modernization efforts without as much risk of losing nuanced human design decisions.
Beyond this directory-level planning, external research has identified several other reasons why tracking AI authorship matters. A CodeRabbit study of 470 pull requests found that AI-authored changes produced roughly 1.7x more issues per PR than human-only changes, with particular spikes in resource inefficiency, concurrency errors, and readability problems. Knowing which code was AI-generated allows teams to prioritize review effort where it's most needed. On the security front, research from Veracode found that approximately 45% of AI-generated code contains security flaws, and that newer or larger models don't necessarily produce more secure output — meaning the problem doesn't simply resolve itself as AI tools improve. Security practitioners at Kiuwan have noted that when teams track which code was AI-generated, what tools were used, and how it was reviewed, security leaders can quickly identify the scope of potential vulnerabilities and implement targeted fixes rather than treating the entire codebase as an undifferentiated surface. A Georgetown CSET report on cybersecurity risks of AI-generated code further highlighted that beyond security vulnerabilities, AI tools can trivially generate large volumes of code that increase an organization's technical debt, making the monitoring and maintenance burden heavier over time.
In short, LLM attribution data helps engineering teams move beyond the binary question of "should we use AI?" and into the more nuanced territory of "where is AI helping, where does it need more oversight, and where can we lean into it even further?" For setup instructions on connecting your AI tool telemetry to GitClear, see Setting up AI usage metrics (GitHub Copilot, Cursor, Anthropic Claude Code).