It's a weird time to be a code measurement or "developer analytics" company.
We have read, researched, and corroborated that 2026 is set to be the year where "percent of AI-authored code" rockets past 50%, to become the default means of code authorship for most people, most of the time.
This is a new era of software-building. We are calling it the Prompt to Production era, because it is easier to discuss named topics than unnamed abstractions. You can call it something else, but pick a name, because 2026 clearly marks a new version of building software. It needs to be discussed.
ChatGPT launched about 3 years ago. That's how long it took to move from AI writing code like "a novice" to "a recent code graduate" to today, writing code like a Senior Developer with mildly severe amnesia. The modern combination of "reasoning harness" and "high-context reasoning models" have opened the floodgates to exploring how much AI can accelerate software building. No informed observer will be shocked if AI-authored code reaches 75% by the end of 2026, but 50% is the floor among estimates:
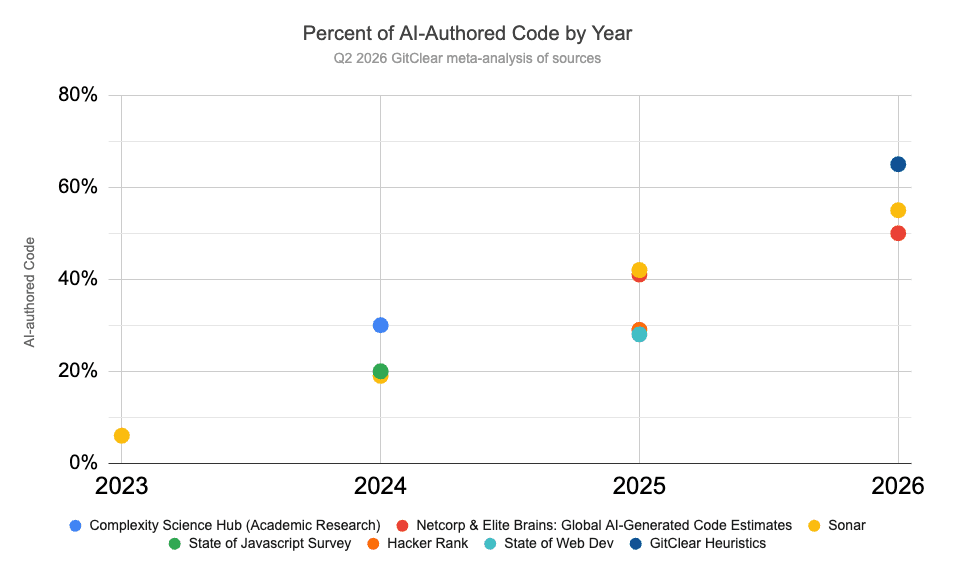
Pre-2026, "75% AI" repos had to be greenfield projects. Asking AI to contribute to enterprise-sized repos had been a shitshow (the technical term) before reasoning harnesses. With Claude Code and similarly-inspired harnesses, we now see AI agents successfully progress for 5-10 minutes in repos of every size.
Consequently, the skills exercised by a value-maximizing developer have shifted.
Since GitClear customers want to estimate the rate at which useful, durable code is being produced, we need to reevaluate what "useful, durable code change" means.
Before AI, we captured "durable rate of code change" in part by utilizing the assumption that valuable code took hours to work out. That assumption lies among several others that have been invalidated by modern tooling. To pinpoint the characteristics of valuable code, it's instructive to think about the Prompt to Production workflow of a Staff Engineer; what are today's experts doing different when they sit down to feast upon their latest project, using the best available frontier tooling?
link♻️ Dev environment in flux: Like always, except not
Fortunately for developers, "change" has been a constant companion. Compared to similarly-compensated trades like Doctor, Lawyer or Electrician, we are more accustomed to having our toolkit changed by new technologies every year, if not month or week.
But Prompt to Production is different from what we've experienced before, because this evolution is the one that shorts our value as code author. Annoyingly, our shortest path toward value creation has become code review. During my LeadDev New York AI talk, I joked that "'reviewing code' vs 'writing it' is like 'watching someone eat ice cream' vs 'eating it.'" Alas, joke's on me, because 2026 marks my debut as "full-time ice cream-watcher." At least I'm in good company with all our customers. 🍨
So far, it's an exaggeration to say that "all of a dev's value is watching code be written," because it's still faster to touch up proposed code than to re-prompt in many cases. Those cases will dwindle as the AI with each passing quarter. Long-term, the value imparted by devs now resides in prompting and recognizing well-factored code. In particular, value emerges from battling AI's predilection toward duplication:
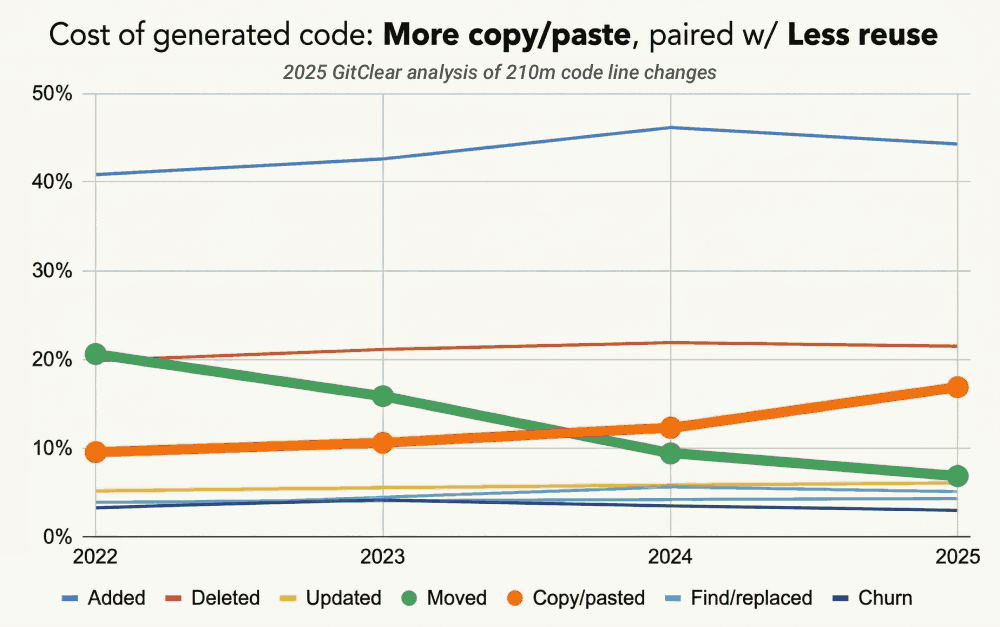
Big picture, several elements of "what made a great engineer" will continue to be "what makes a great engineer." The most valuable will be those who can
Envision the most concise set of (preferably pre-existing) interrelated models to deliver management's product vision
Answer "where in the repo is the current pattern repeated?" to combat AI's strong tendency toward "build by adding more and more"
Remove code whenever possible, ensure test coverage for code that can't be removed
Generally speaking, Prompt to Production companies will need engineers who can answer "what context can encourage LLMs to transform our v1 features into v2 features, with as little newly added code as possible?"
In a world where AI's default behavior is "add v1 features," the greatest Staff Engineer value emerges from "discovering," "connecting," and "extending" existing systems. This is what a useful "durable code measurement" metric should now capture.
link💼 Six differences in our barometer of "valuable code"
With this framework for value creation in mind, let's turn attention to the Diff Delta metric that GitClear has been evolving over nearly 10 years. "Success" is defined here as maintaining an edge over Commit Count in correlation with Story Points. Following are 6 adaptations we've made to Diff Delta to reflect what "value" now means in the Prompt-to-Production era.
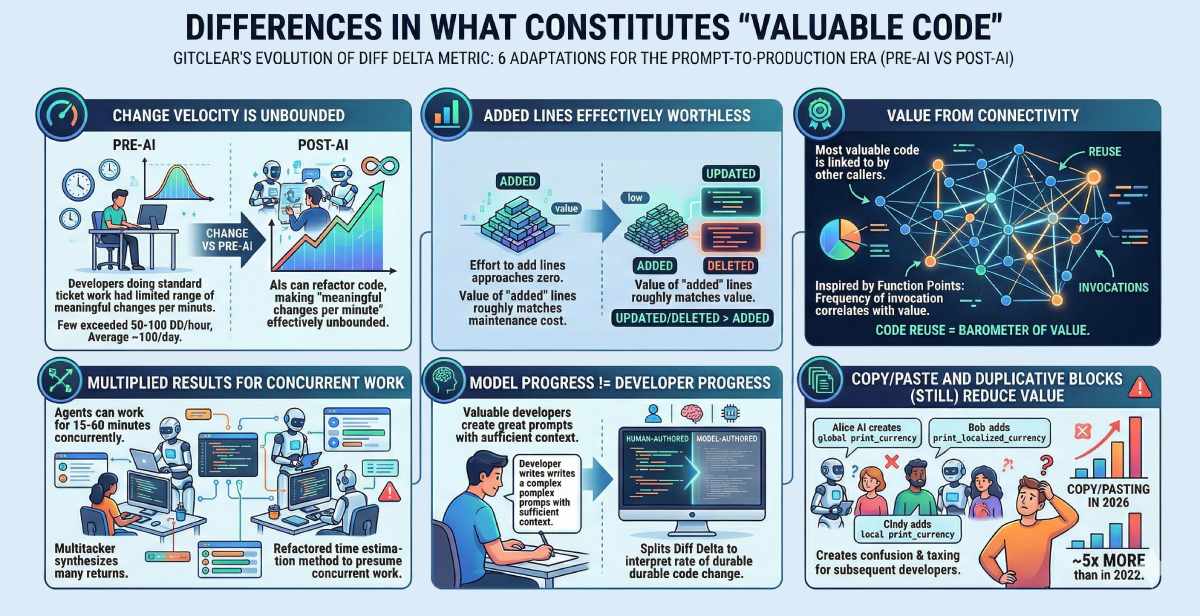
Diff Delta updates from the past quarter
link1. Change velocity is unbounded
Prior to 2024, it was possible for a metric like Diff Delta to effectively circumscribe the potential range of the Diff Delta change metric, because developers doing standard ticket work could only write, update or delete code within a limited range of "meaningful changes per minute" (very few developers exceeded 50-100 Diff Delta/hour, most averaged 100 per day). Now that AIs can be persuaded to refactor code rather than just adding to it, the "meaningful changes per minute" is effectively unbounded.
link2. Multiplied results for concurrent work
With agents that can work for 15-60 minutes, there's a new chance for overachievers to recognize tasks that can be implemented concurrently. Of course, concurrent work risks quality if the author isn't dedicated to vigorous code review. But the multitasker can synthesize the returns of many talented programmers. Thus, we have refactored our "time estimation" method to presume that it is common for developers to toggle between different projects concurrently.
link3. Added lines effectively worthless
We have always believed that "Updated" and "Deleted" lines were more valuable than "Added" lines. But, a few years ago, "added" lines still meant that useful effort was being expended. As the effort of adding a line approaches zero, whatever value "added" lines deliver is roughly matched by the cost of having more code to maintain.
link4. Model progress != developer progress
Valuable developers are engines that create great prompts. A "great prompt" is one crafted with sufficient context to fuse with the existing framework, yielding as few new lines of code as possible. To interpret the developer's "rate of durable code change," GitClear now splits Diff Delta between a "human-authored" fraction and a "model-authored" fraction. This helps managers recognize whose prompts are creating the greatest positive impact, to learn what techniques and models are being used.
link5. Value from connectivity
To what extent is the code integrated with existing methods? Like Page Rank, the most valuable code tends to be linked to (i.e., invoked) by other callers. This measure is inspired in part by the IEEE-ratified measurement of "Function Points." Extensive research on Function Points suggests that "frequency of invocation" correlates with value. In other words, "code reuse" is a barometer of "value created."
link6. Copy/paste and duplicative blocks (still) reduce value
While LLMs have begun to show more aversion to copy/paste vs. past years, there is still around 5x more copy/pasting in 2026 than was measured in 2022. Let's dig deeper into why this is so important.
link🤝 Why "connect," "reuse" and "extend" underpin value creation
Why is reusing code more valuable than it had been before Prompt to Production?
Because it's free to add code. Anyone can build their own mountain of features without knowing if its in C++ or ancient sea scroll. This has always been true to an extent - Junior Devs have always been proficient at building individual features. A new graduate I once worked with was renowned for always building his own unique helper functions for every menu he created.
The "add and then add more" approach has been historically unappealing among Senior Developers thanks to the speed at which its warts accumulate:
New code = untested code. Every code file added to a repo is a future home to bugs. More files => more lines => more defects is an uncontested proposition, other things being equal.
Default undocumented. Every new file or function needs to be comprehended by maintainers. Chances are, it won't have documentation at first. The more times a file/function is reused, the greater the odds someone will take time to document parameter types & such
Useful software goes deep. To sustain a SaaS business, its product must offer value far beyond what a customer could hope to build themselves. The key to "far beyond what a customer could build" is architecting interconnected systems that remain flexible enough to evolve.
Harder to move. Every code file added to a repo adds burden whenever it (or its dependencies) are asked to evolve for changing circumstances
Harder to reference, harder to fit in context. Yes, modern LLMs are getting ever-larger context windows. But there are questions about "how well will it recall the first 10k tokens of a 1 million context block?" Or more prosaically, if you're making a query without knowing which files to reference, the difficulty of providing all relevant files is proportional to how much the philosophy is "add and then add more"
We're all degrees of ADHD. The greater the count of files in a repo, the less likely we'll have energy to understand them all. The greater the extent that the team embraces "adding more free code," the less likely anyone will have enough attention to comprehend how this repo connects together later.
The "which one?" burden. This problem is so common and terrible that it deserves its own paragraph outside the list.
Whereas some of the "adding code drawbacks" require having been a programmer to relate to, I think the "Which one?" burden can be easily comprehended by anybody.
Let’s say you are a developer implementing a new sales page, and you’re charging through your todo list, laying it to waste, until your reach the last item, "Internationalization." Thankfully, many developers before you have also built sales pages, and they needed a way to internationalize as well.
You need to translate your sales page to other languages...
Before AI, you would look up and find a function called | After AI, somebody else's AI suggested that they use an improved version of the | And then, another teammate's AI needed an extra parameter for their sales so it adds |
Their productivity looked high. The AI didn’t break anything. Life was humming along quite smoothly.
Until you reached this "Internationalize" task on your list. Now your options range from "ugh" to "ugggghhh"
Why are there three of these methods in the first place?
Should I be a good citizen and remove the lesser used versions of it so the next person does not experience this impromptu code review session?
If I am a good citizen, will it break something in the existing code that called translateSpecial?
It is no exaggeration that situations like these can easily consume more time to resolve than the main task the developer had intended to work on. This is why it is so imperative not to let duplication fester like a malevolent gravity.
link❓ What's missing?
Do you think about AI ROI, as a developer or a manager?
Do you think about what "actionable changes" you would make on the basis of the data that you received about how AI was impacting yourself and your team?
We want to hear answers bad enough that we'll sweeten the pot with a product offer, described below [1]. Post to this blog's comments (below) 3 action-oriented questions you have wondered about your team's use of AI, or AI ROI in general (100 word min). For example:
Which devs on the team are using prompts best, and what models do they tend to use? This can teach us who to ask about their querying approach.
How much did each PR fuse with the outside code? [For "high" values] How much "add v1 features" code was sidestepped?
What happens to code review? If we're all full-time code reviews, dumping our self-reviewed PR into a funnel of teammates self-reviewed PRs, how does that factorial combination resolve? Presumably it becomes necessary to conditionally automate code review? How best?
No copying from the examples or from fellow commenters 😉 If you answer three, and you live in the US or somewhere with US-comparable postage costs, pick a t-shirt size/color and email hello@gitclear.com your choice & address.
[1] Very soft shirts, they come in desert sand and dark grey color. Sure to amuse your friends and spike your enemies' jealous ruminations.
